Fast Point Feature Histograms (FPFH) descriptors
The theoretical computational complexity of the Point Feature Histogram (see
Point Feature Histograms (PFH) descriptors) for a given point cloud 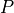 with
with 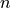 points
is
points
is 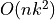 , where
, where 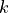 is the number of neighbors for each point
is the number of neighbors for each point
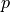 in . For real-time or near real-time applications, the
computation of Point Feature Histograms in dense point neighborhoods can
represent one of the major bottlenecks.
in . For real-time or near real-time applications, the
computation of Point Feature Histograms in dense point neighborhoods can
represent one of the major bottlenecks.
This tutorial describes a simplification of the PFH formulation, called Fast
Point Feature Histograms (FPFH) (see [RusuDissertation] for more information),
that reduces the computational complexity of the algorithm to 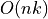 ,
while still retaining most of the discriminative power of the PFH.
,
while still retaining most of the discriminative power of the PFH.
Theoretical primer
To simplify the histogram feature computation, we proceed as follows:
in a first step, for each query point
a set of tuples
between itself and its neighbors are computed as described in Point Feature Histograms (PFH) descriptors - this will be called the Simplified Point Feature Histogram (SPFH);
in a second step, for each point its
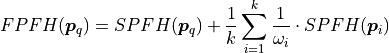
where the weight 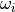 represents a distance between the query point
and a neighbor point
represents a distance between the query point
and a neighbor point 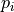 in some given metric space, thus
scoring the (
in some given metric space, thus
scoring the (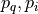 ) pair, but could just as well be selected as a
different measure if necessary. To understand the importance of this weighting
scheme, the figure below presents the influence region diagram for a
k-neighborhood set centered at .
) pair, but could just as well be selected as a
different measure if necessary. To understand the importance of this weighting
scheme, the figure below presents the influence region diagram for a
k-neighborhood set centered at .
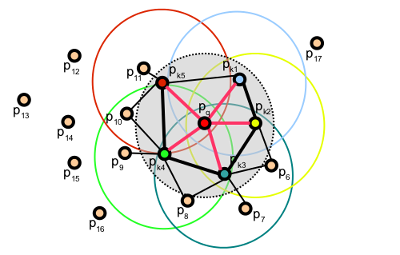
Thus, for a given query point , the algorithm first estimates its
SPFH values by creating pairs between itself and its neighbors (illustrated
using red lines). This is repeated for all the points in the dataset, followed
by a re-weighting of the SPFH values of using the SPFH values of its
neighbors, thus creating the FPFH for . The extra FPFH
connections, resultant due to the additional weighting scheme, are shown with
black lines. As the diagram shows, some of the value pairs will be counted
twice (marked with thicker lines in the figure).
Differences between PFH and FPFH
The main differences between the PFH and FPFH formulations are summarized below:
the FPFH does not fully interconnect all neighbors of
the PFH models a precisely determined surface around the query point, while the FPFH includes additional point pairs outside the r radius sphere (though at most 2r away);
because of the re-weighting scheme, the FPFH combines SPFH values and recaptures some of the point neighboring value pairs;
the overall complexity of FPFH is greatly reduced, thus making possible to use it in real-time applications;
the resultant histogram is simplified by decorrelating the values, that is simply creating d separate feature histograms, one for each feature dimension, and concatenate them together (see figure below).
Estimating FPFH features
Fast Point Feature Histograms are implemented in PCL as part of the pcl_features library.
The default FPFH implementation uses 11 binning subdivisions (e.g., each of the four feature values will use this many bins from its value interval), and a decorrelated scheme (see above: the feature histograms are computed separately and concatenated) which results in a 33-byte array of float values. These are stored in a pcl::FPFHSignature33 point type.
The following code snippet will estimate a set of FPFH features for all the points in the input dataset.
1#include <pcl/point_types.h>
2#include <pcl/features/fpfh.h>
3
4{
5 pcl::PointCloud<pcl::PointXYZ>::Ptr cloud (new pcl::PointCloud<pcl::PointXYZ>);
6 pcl::PointCloud<pcl::Normal>::Ptr normals (new pcl::PointCloud<pcl::Normal> ());
7
8 ... read, pass in or create a point cloud with normals ...
9 ... (note: you can create a single PointCloud<PointNormal> if you want) ...
10
11 // Create the FPFH estimation class, and pass the input dataset+normals to it
12 pcl::FPFHEstimation<pcl::PointXYZ, pcl::Normal, pcl::FPFHSignature33> fpfh;
13 fpfh.setInputCloud (cloud);
14 fpfh.setInputNormals (normals);
15 // alternatively, if cloud is of tpe PointNormal, do fpfh.setInputNormals (cloud);
16
17 // Create an empty kdtree representation, and pass it to the FPFH estimation object.
18 // Its content will be filled inside the object, based on the given input dataset (as no other search surface is given).
19 pcl::search::KdTree<PointXYZ>::Ptr tree (new pcl::search::KdTree<PointXYZ>);
20
21 fpfh.setSearchMethod (tree);
22
23 // Output datasets
24 pcl::PointCloud<pcl::FPFHSignature33>::Ptr fpfhs (new pcl::PointCloud<pcl::FPFHSignature33> ());
25
26 // Use all neighbors in a sphere of radius 5cm
27 // IMPORTANT: the radius used here has to be larger than the radius used to estimate the surface normals!!!
28 fpfh.setRadiusSearch (0.05);
29
30 // Compute the features
31 fpfh.compute (*fpfhs);
32
33 // fpfhs->size () should have the same size as the input cloud->size ()*
34}
The actual compute call from the FPFHEstimation class does nothing internally but:
for each point p in cloud P
1. pass 1:
1. get the nearest neighbors of :math:`p`
2. for each pair of :math:`p, p_i` (where :math:`p_i` is a neighbor of :math:`p`, compute the three angular values
3. bin all the results in an output SPFH histogram
2. pass 2:
1. get the nearest neighbors of :math:`p`
3. use each SPFH of :math:`p` with a weighting scheme to assemble the FPFH of :math:`p`:
Note
For efficiency reasons, the compute method in FPFHEstimation does not check if the normals contains NaN or infinite values. Passing such values to compute() will result in undefined output. It is advisable to check the normals, at least during the design of the processing chain or when setting the parameters. This can be done by inserting the following code before the call to compute():
for (int i = 0; i < normals->size(); i++)
{
if (!pcl::isFinite<pcl::Normal>((*normals)[i]))
{
PCL_WARN("normals[%d] is not finite\n", i);
}
}
In production code, preprocessing steps and parameters should be set so that normals are finite or raise an error.
Speeding FPFH with OpenMP
For the speed-savvy users, PCL provides an additional implementation of FPFH estimation which uses multi-core/multi-threaded paradigms using OpenMP to speed the computation. The name of the class is pcl::FPFHEstimationOMP, and its API is 100% compatible to the single-threaded pcl::FPFHEstimation, which makes it suitable as a drop-in replacement. On a system with 8 cores, you should get anything between 6-8 times faster computation times.